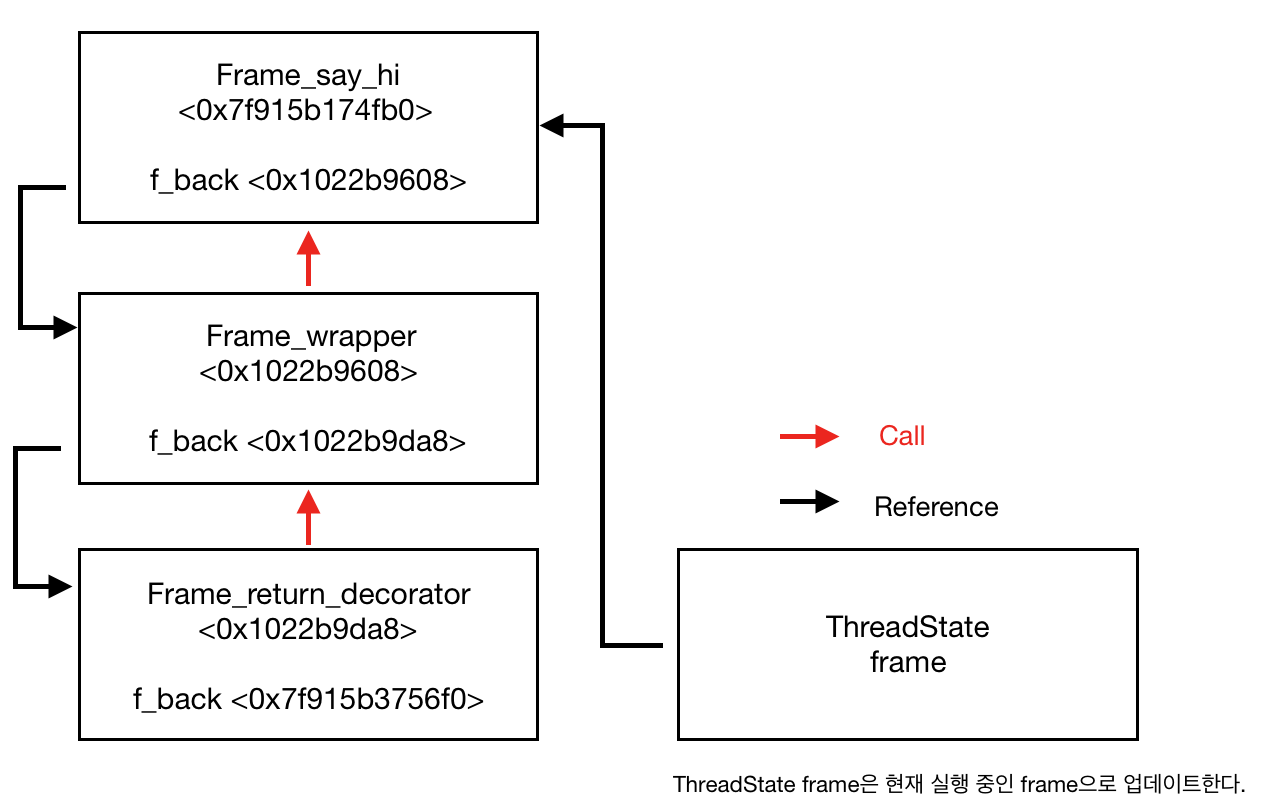
iterator와 generator
generator를 이해하기전에 먼저 iterator에 대해 간단히 알아보자.
iterator는 list, set, dictionary, str, bytes, tuple, range와 같은 iterable한 타입이나 collections을 차례로 꺼낼 수 있는 객체이다. generator 또한 iterable한데, 해야 할 일을 마치면 반환하지 않고 대기 상태가 된다. 그 후 다시 호출되면 일을 이어서 진행하는 특징을 가지고 있다. 또한 generator는 lazy iterator로서 메모리 리소스를 적게 쓸 수 있다. 이러한 특징으로 거대한 양의 iterable한 객체들을 다룰 때, 무한 sequence를 다룰 때 사용된다.
예제) large files 다룰 때
csv_list = csv_reader("huge_csv.txt")
row_content = 0
for row in csv_list:
row_count += 1
print(f"Row count is {row_count}")
def csv_reader(file_name):
file = open(file_name)
result = file.read().split("\n")
return result
아주 큰 csv파일을 열어 \n으로 쪼개어 result에 담게되면 MemoryError 혹은 시스템이 느려지는 상황이 발생할 것이다.
이러한 상황을 회피할 수 있는 방법중 하나가 generator를 사용하는 것이다.
def csv_reader(file_name):
for row in open(file_name, "r"):
yield row
Row count is 912349023 # Awesome!
위 예제를 보면 csv_reader에 yield가 추가 되었다. 함수에 yield가 있으면 generator가 만들어지게 된다 (yield는 나중에 좀 더 자세히 살펴보기로하고) yield를 만난 iterator는 실행을 잠시 중단하고 caller에게 값(generator object)을 전달하는 것이다. 이는 iterator가 StopIteration을 만나기전까지 반복하여 실행된다.
generator type
generator는 두 가지 타입이 있는데 하나는 위 예제에서 볼 수 있는 yield를 가지는 functions과 generator expressions이다.
def csv_reader(file_name):
file = open(file_name)
return (row for row in file.read().split("\n")) # generator expressions
예제) 무한한 시퀀스를 생성할 때
def infinite_seq():
num = 0
while True: # infinite ...
yield num # gernerator!
num += 1
>>> for i in infinite_seq():
... print(i, end=" ")
...
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
30 31 32 33 34 35 36 37 38 39 40 41 42
[...]
6157818 6157819 6157820 6157821 6157822 6157823 6157824 6157825 6157826 6157827
6157828 6157829 6157830 6157831 6157832
KeyboardInterrupt
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
위 예제를 통해 generator는 KeyboardInterrupt가 발생하지 않는다면 무한히 값을 찍어낸다.
함수가 실행될 때 generator는 loop를 이용하지 않고도 next()함수를 이용하여 순차적으로 실행할 수 있는데 iterator object안에는 __next__()가 있기 때문이다. next()에 의해 실행되는 generator는 할 일을 마치면 대기상태에 들어갔다가 일을 이어한다는 것을 확인할 수 있다.
>>> gen = infinite_sequence()
>>> next(gen)
0
>>> next(gen)
1
generator의 성능
앞서 살펴보았듯 generator는 메모리를 최적으로 사용하기에 상당히 좋은 방법이였다. 실제 list와 generator의 메모리 사이즈를 sys.getsizeof()를 이용하여 살펴보겠다.
>>> import sys
>>> nums_squared_lc = [i*2 for i in range(100000)]
>>> sys.getsizeof(nums_squared_lc)
824464
>>> nums_suared_gc = (i*2 for i in range(100000))
120
list의 경우 824,464 bytes이고 generator의 경우 120 bytes이다. list가 generator에 비해 약 700배의 메모리 공간을 가지게된다.
하지만, 공간이 아닌 속도를 살펴보면 결과가 어떨까?
>>> import cProfile
>>> cProfile.run('sum([i*2 for i in range(100000)])')
100005 function calls in 0.025 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
100001 0.014 0.000 0.014 0.000 <string>:1(<genexpr>)
1 0.000 0.000 0.025 0.025 <string>:1(<module>)
1 0.000 0.000 0.025 0.025 {built-in method builtins.exec}
1 0.011 0.011 0.025 0.025 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
>>> cProfile.run('sum((i*2 for i in range(100000)))')
5 function calls in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
10001 0.002 0.000 0.002 0.000 <string>:1(<genexpr>)
1 0.000 0.000 0.003 0.003 <string>:1(<module>)
1 0.000 0.000 0.003 0.003 {built-in method builtins.exec}
1 0.001 0.001 0.003 0.003 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
위 결과값을 보면 list의 경우 generator보다 약 2.5배 빠른것을 살펴볼 수 있다.
따라서 풀어야하 할 문제는 공간과 속도를 고려해 적절한 타입을 선택해 해결해야한다.
yield
yield를 가지는 functions은 generator이다. yield를 통해 callee는 pause되고 caller에게 값을 던져준다. 이는 StopIteration을 만날때까지 이어진다.
>>> def multi_yield():
... y_str = "Fisrt yield"
... yield y_str
... y_str = "Second yield"
... yield y_str
>>> import dis
>>> dis.dis(multi_yield)
2 0 LOAD_CONST 1 ('First yield')
2 STORE_FAST 0 (yield_str)
3 4 LOAD_FAST 0 (yield_str)
6 YIELD_VALUE
8 POP_TOP
4 10 LOAD_CONST 2 ('Second yield')
12 STORE_FAST 0 (yield_str)
5 14 LOAD_FAST 0 (yield_str)
16 YIELD_VALUE
18 POP_TOP
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
위 예제의 8라인을 보면 yield를 통해 POP_TOP으로 top-of-stack을 지워버릴 뿐 함수를 반환하지 않는것을 살펴볼 수 있다. 이 때 caller에게 값을 넘겨주고 pause상태에 들어간다.
지금까지는 yield를 통해 caller에게 callee가 값을 넘겨주기만 한다. 즉 일방향이다. 양방향으로 값을 주고 받을 순 없을까? 해답은 바로 send()이다.
send()를 통한 coroutine
generator는 yield를 통해서 값을 caller에게 넘겨주는데 반대로 caller가 값을 넘겨주고 싶을 때 바로 send()를 사용한다.
def score_generator():
score = 0
default = 0.5
while True:
incr = yield score # caller에게 score를 넘긴다.
score += incr if incr is not None else default
>>> s_gen = score_generator()
>>> next(s_gen)
0
>>> next(s_gen)
0.5
>>> next(s_gen)
1
>>> s_gen.send(5)
6
>>> s_gen.send(1.5)
7.5
>>> next(s_gen)
8
send()함수를 이용해 yield를 실행하는 지점에 값을 callee에게 줄 수 있다. 이 기법이 바로 generator기반의 coroutine이며 python3에서는 이를 native coroutine으로 발전시켰다.
throw()와 close()
특정한 상황에서 generator를 종료(default: StopIteration)하고 싶다면 throw()나 close()를 사용하면 된다.
>>> s_gen = score_generator()
>>> for s_g in s_gen:
... accum_score = s_gen.send(1)
... print(accum_score)
... if accum_score > 1:
... s_gen.throw(ValueError("Accum_score large then 5"))
... # s_gen.close()
ValueError Traceback (most recent call last)
<ipython-input-80-2bb73b6a4b0a> in <module>
3 accum_score = s_gen.send(1)
4 if accum_score > 1:
----> 5 s_gen.throw(ValueError("Accum_score large then 5"))
6 # s_gen.close()
7
<ipython-input-72-0198c1120a1c> in score_generator()
3 default = 0.5
4 while True:
----> 5 incr = yield score # caller에게 score를 넘긴다.
6 score += incr if incr is not None else default
7
ValueError: Accum_score large then 5
결론
- python의 generator의 특징과 선언법을 알아봤다.
- 해결할 문제에 공간과 속도를 고려해 generator를 선택할 수 있다.
- generator 기반의 coroutine을 살펴보았기 때문에 비동기식 프로그래밍을 이해할 수 있는 준비가 되었다.
reference